400-0731-162牛耳教育报名热线

400-0731-162牛耳教育报名热线

什么是爬虫:自动提取数据的程序。
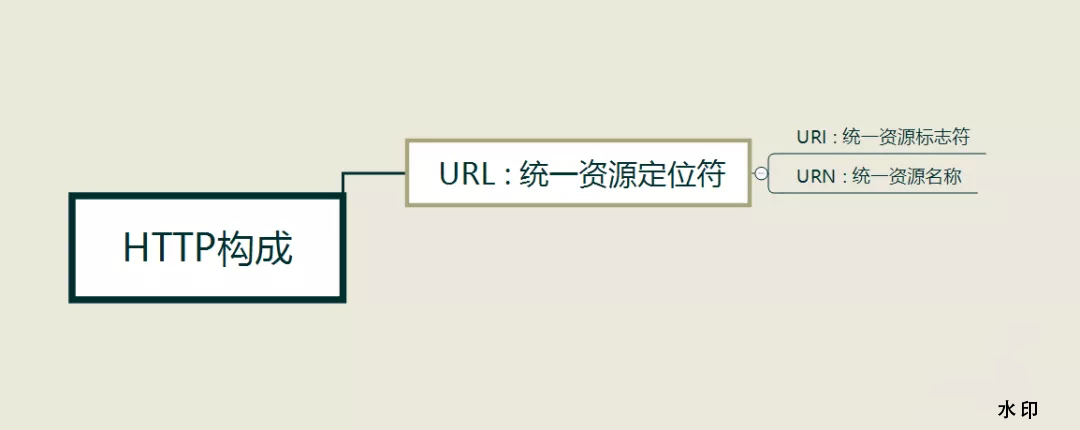
HTTP :
- URI : 统一资源标志符
- URL : 统一资源定位符
- URN : 统一资源名称
例如: https://github.com/favicon.ico 是 github 的网站图标链接,它是一个 URL,也是一个 URI
URI 是 URL 的子集
URL 由 URI 和 URN 构成
超文本「hypertext」
在浏览器里看到的网页就是超文本解析而成的,其网页源码是一系列HTML 代码,里面包含了一系列标签,比如 img 显示图片,p 指定显示段落等
浏览器解析这些标签后,便形成了平时看到的网页,而网页的源码HTML 就可以称作超文本。如下面右边的「代码」:
HTTP : 超文本传输协议
HTTPS : 是以安全为目标的 HTTP 通道,即 HTTP 下加入了 SSL 层,简 称 HTTPS
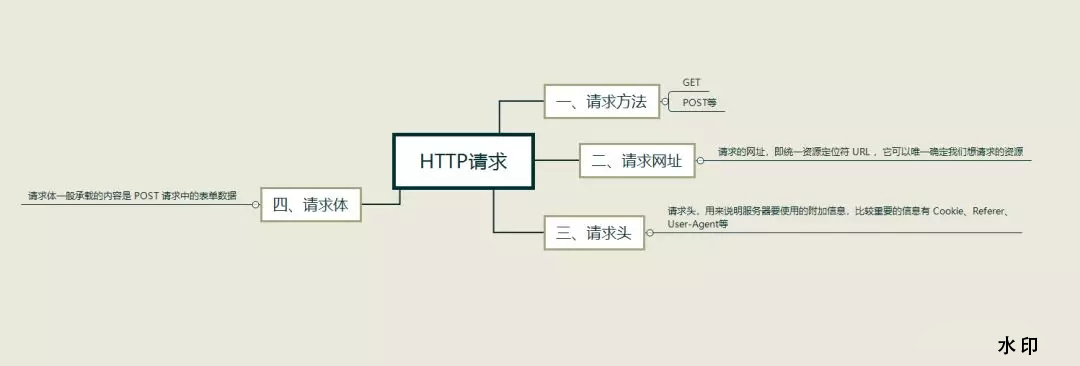
HTTP 请求
请求,由客户端向服务端发出,可以分为4 部分内容 :
请求方法、-请求网址、请求头、请求体,其逻辑关系如下:

1、请求方法
- GET: 请求页面,并返回页面内容
- POST : 大多用于提交表单过上传文件,数据包含在请求中
- HEAD : 类似于 GET 请求,只不过返回的相应中没有具体的内容,用于 获取报头
- PUT : 从客户端向服务器传送的数据取代指定文档的内容
- DELETE : 请求服务器删除指定的页面
- CONNECT : 把服务器当作跳板,让服务器代替客户端访问其他网页
- OPTIONS : 允许客户端查看服务器的性能
- TRACE : 回显服务器收到的请求,主要用于测试或诊断
例如,在百度中搜索python,这就是一个 GET 请求,链接为 https://www.baidu.com/s?wd=python,其中 URL 中包含了请求的参数信息,这里参数 wd 表示要搜寻的关键字。POST 请求大多在表单提交时发起,比如,对于一个登录表单,输入用户名和密码后,点击 "登录" 按钮,这通常会发起一个 POST 请求,其数据通常以表单的形式传输,而不会体现在 URL 中。
2、请求的网址
请求的网址,即统一资源定位符URL ,它可以唯一确定我们想请求的资源。
3、请求头
请求头,用来说明服务器要使用的附加信息,比较重要的信息有Cookie、Referer、User-Agent等
- Accept : 请求报头域,用于指定可接受哪些类型的信息
- Accept-Language : 指定客户端可接受的语言类型
- Accept -Encoding : 指定客户端可接受的内容编码
- Host : 用于指定请求资源的主机 IP 和端口号,其内容为请求 URL 的原始服务器或网关的位置
- Cookie : 网站为了辨别用户进行会话跟踪而存储在用户本地的数据,主要功能是维持当前访问会话
- Referer : 此内容用来标识这个请求是从哪个页面发过来的
- User-Agent : 简称 UA ,是一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本、浏览器等版本信息 。再做爬虫时加上此信息,可以伪装为浏览器; 如果不加,很可能会被识别出为爬虫
- Content-Type : 互联网媒体类型或者 MIME 类型,在 HTTP 协议消头中,它用来表示具体请求中的媒体类型信息
4、请求体
请求体一般承载的内容是POST 请求中的表单数据
响应
响应,由服务端返回给客户端,可以分为三部分,响应状态代码、响应头和响应体
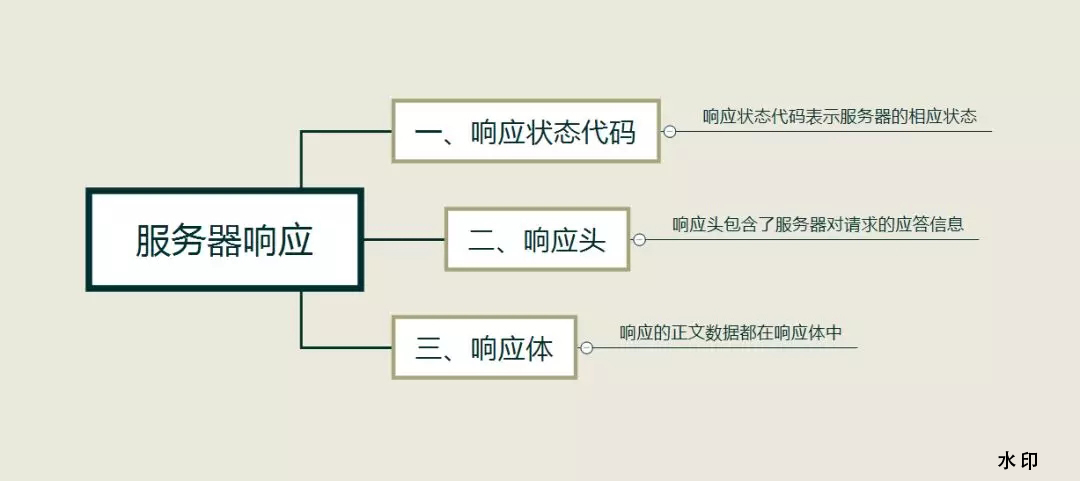
响应状态代码
响应状态代码表示服务器的相应状态
响应头
响应头包含了服务器对请求的应答信息
响应体
响应的正文数据都在响应体中,「在做爬虫时,主要通过响应体得到网页的源码、JSON数据等,然后从中 做响应内容的提取」






咨询热线
400-0731-162

